
MySQL优化-LIMIT查询
在业务开发中,分页查询 是经常碰到的接口功能之一,一般分页查询都会使用有顺序性的字段作为排序字段,例如更新时间、创建时间、等级。。。
假如现在系统中有这样一张表t:

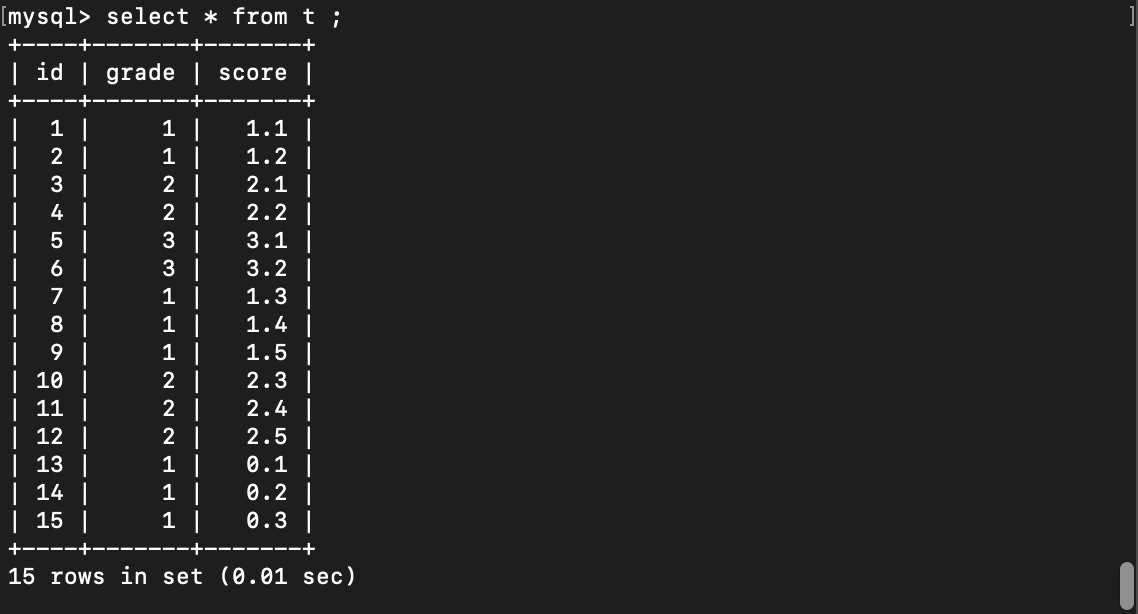
id为主键,grade表示等级,score表示分数,业务中一个等级表示一个分数范围,现有如下数据:
数据范围模拟分布如下:
grade == 1: score < 2
grade == 2: 2 <= score < 3
grade == 3: score >= 3
现在有一个分页查询:要求用等级升序排序,每页查询5条数据
一开始的sql如下:
1 | -- 第一页 |
理想情况下,第一页查询结果应该是:
1 | (1, 1.1) |
第二页的查询结果应该是:
1 | (1, 0.1) |
可实际情况是:
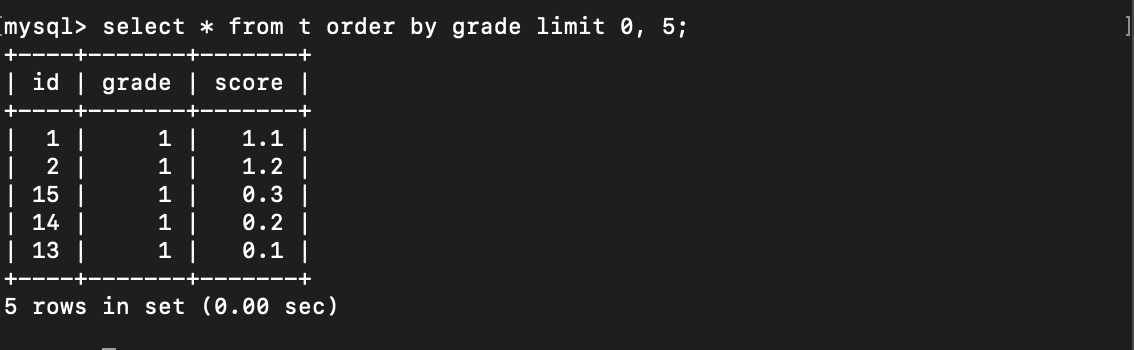
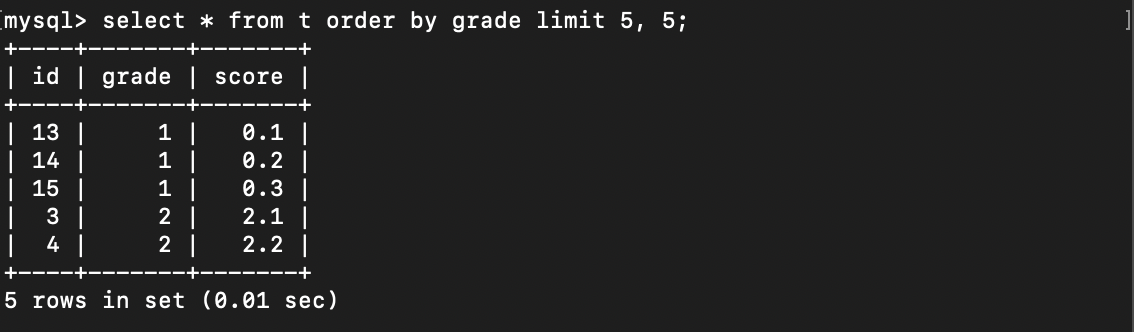
从这里可以大致猜到:
-
如果 ORDER BY 的字段,存在相同值,并且 相同值的数据量 > limit的数量,MySQL不会对符合ORDER BY条件的所有行进行内部排序,而是随机读取。
-
按照 innodb 索引树的规则(相同索引值,按照聚簇索引列有序排序),这个查询语句应该是没有使用到 i_grade 索引树的。
执行一下EXPLAIN,看看MySQL优化器的解析计划:
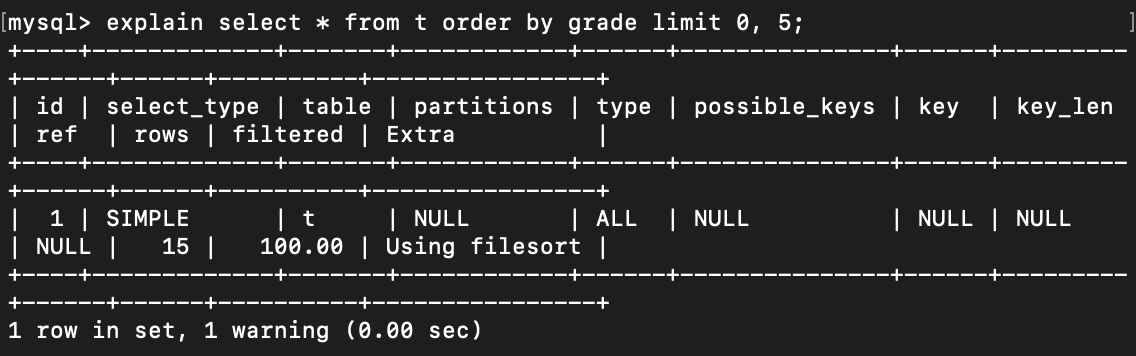
表t上是有grade的索引的,possible_keys却没有解析到,更别说使用到了,那感觉就是MySQL优化器认为走聚簇索引再内部排序更快。
既然如此,那么强制让查询数据使用 i_grade 索引试试:
1 | select * from t force index(i_grade) order by grade limit 0,5; |
查询结果如下:
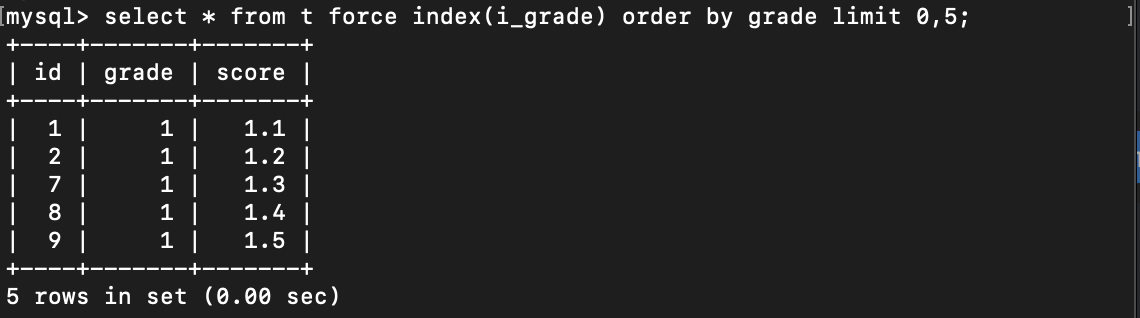
查询结果与预期结果一致了,那证明 i_grade 索引树的存储规则肯定是没问题的,只是MySQL优化器使用的执行计划与预期不一致。
再看下第二页:

第二页的查询结果与预期结果也是一致的,所以问题就出在了MySQL优化器上,两个问题:
- 为什么不使用 ORDER BY 指定列上包含的索引?
- 为什么 Using filesort 排序的结果集不是按照聚簇索引有序排序的?
直接上官方解释:
https://dev.mysql.com/doc/refman/8.0/en/limit-optimization.html
对于文档说明总结如下:
- ORDER BY(GROUP BY)的排序结果会受 LIMIT row_count 的 row_count 影响,如果指定了row_count,MySQL在通常情况下更愿意使用全表扫描,即使可能使用索引会更快。
- MySQL 使用 filesort 排序时,如果查询命令携带 LIMIT row_count ,那么MySQL只会对扫描到的这些数据(row_count行数据)做排序。
解决方案:
在 ORDER BY 后加上其他列,这个最好是有顺序性并且唯一的,例如id。

解析计划如下:
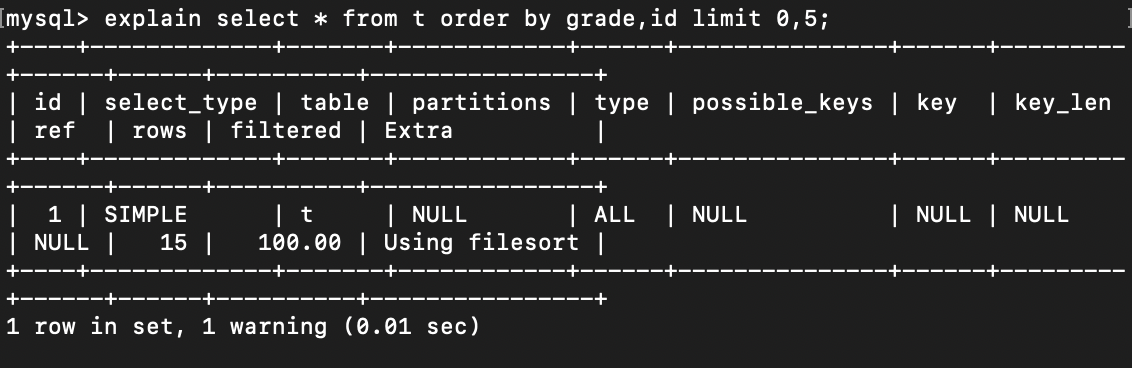
可见它默认还是走的全表扫描,并使用filesort排序,但是此时需要对 id 进行排序,所以保证了数据是按照预期读取的。




