
Java SPI机制分析
SPI是什么
SPI全称为Service Provider Interface,直译就是服务提供方的接口。一种用于定义服务提供商与应用程序之间通信的接口,通常用于实现模块化和可插拔的系统。
Q:为什么会有SPI这种机制?
A:因为在Java面向对象编程中,基于开闭原则和解耦的需要,一般建议用接口进行模块之间的通信编程,通常情况下调用方模块是不会感知到被调用方模块的内部具体实现。
为了实现在模块装配的时候不用在程序里面动态指明,这就需要一种服务发现机制。Java SPI 就是提供了这样一个机制:为某个接口寻找服务实现的机制。这有点类似 IoC 的思想,将装配的控制权移交到了程序之外。
Java SPI机制
Java实现SPI机制的核心类叫 ServiceLoader ,Java的SPI实现约定了以下两件事:
- 文件必须放在META-INF/services/目录底下,并且必须使用UTF-8编码。
- 文件名必须为接口的全限定名,内容为接口实现的全限定名。
示例
第一步,定义一个接口,以及它的实现类。
1 | public interface EventListener { |
1 | public class PrinterEventListener implements EventListener { |
1 | public class BackupEventListener implements EventListener { |
第二步,在 META-INF/services 目录下创建 EventListener 类的全限定名的文件,文件内容为 PrinterEventListener、BackupEventListener 类的全限定名。


第三步,定义一个测试类,使用Java的 ServiceLoader 加载文件,并发起调用。
1 | public class JavaSpiDemo { |
测试结果:

此时成功通过Java SPI获取到了实现类。
实现原理
通过测试类 JavaSpiDemo 的代码大致可知,首先通过 ServiceLoader 加载指定类 ,然后获取到一个迭代器,迭代器的元素就是指定类的实现类。
Q:为什么通过ServiceLoader加载的是“指定类”,而不是接口?
A:因为提供者提供的类也可以是抽象类,实现类可以通过extends继承的方式实现。Java SPI 判断文件中的类是否为实现类的方式就是 Class.isInstance(Object obj) 方法,该方法等同于 instanceof 。
先看加载原理:
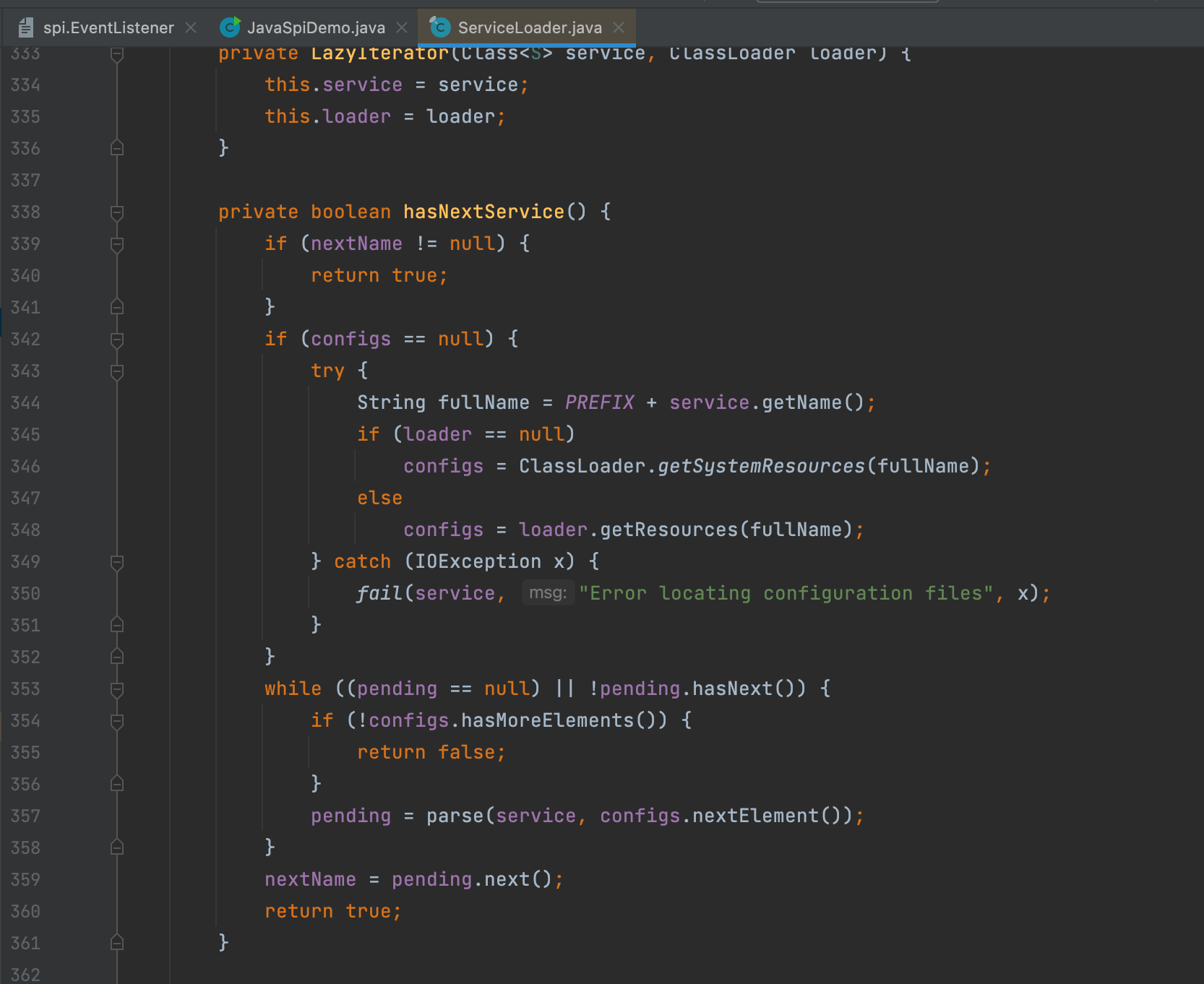
首先获取一个fullName,其实就是 META-INF/services/ 指定类的全限定名。
然后通过ClassLoader获取到资源,其实就是接口的全限定名文件对应的资源,然后交给 parse 方法解析资源。
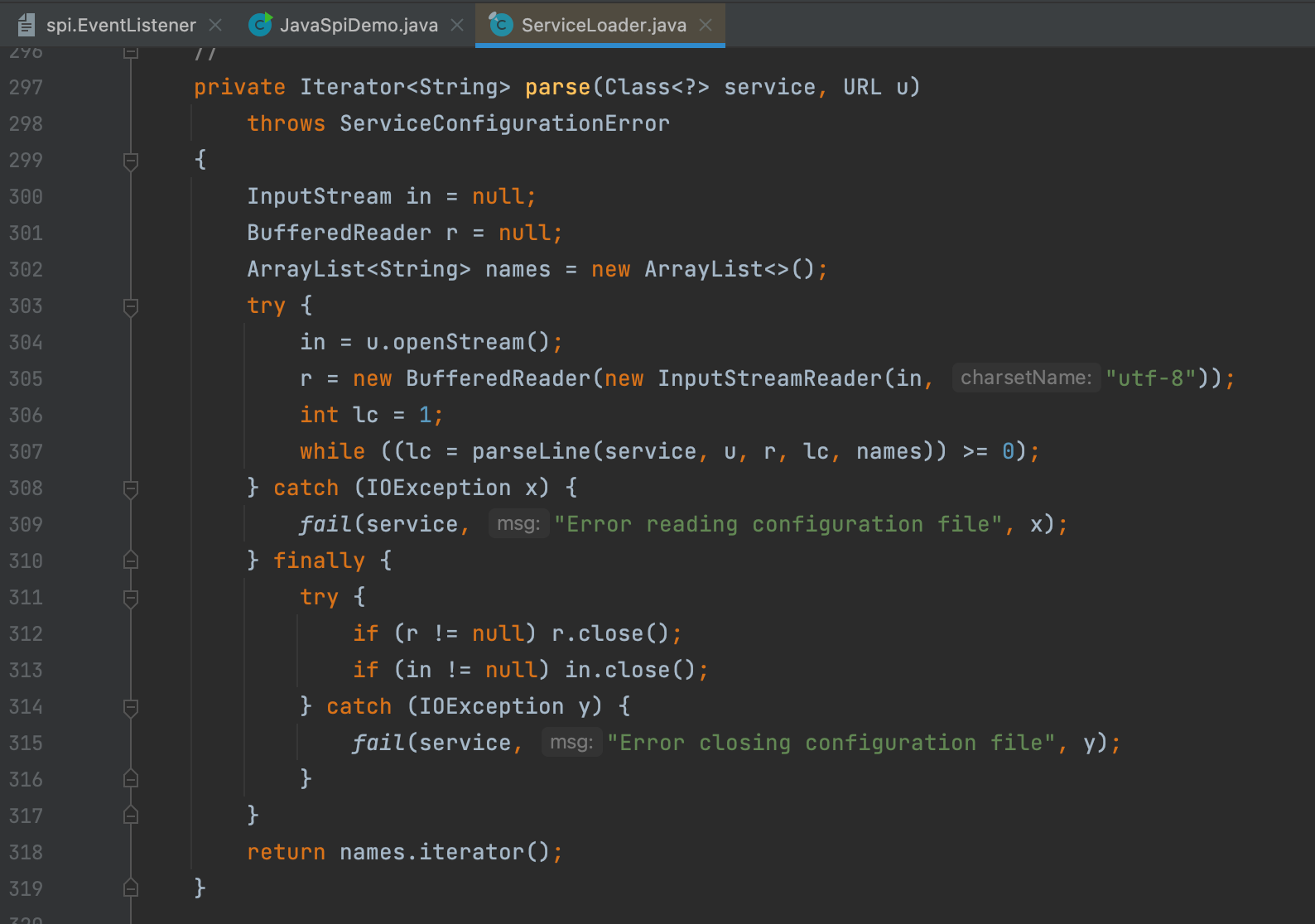

parse方法其实就是通过IO流读取文件的内容,然后通过 parseLine 方法获取实现类的全限定名。
最后在迭代器调用 next 方法时,调用内部的 nextService 方法,通过反射构造实现类的实例化对象。
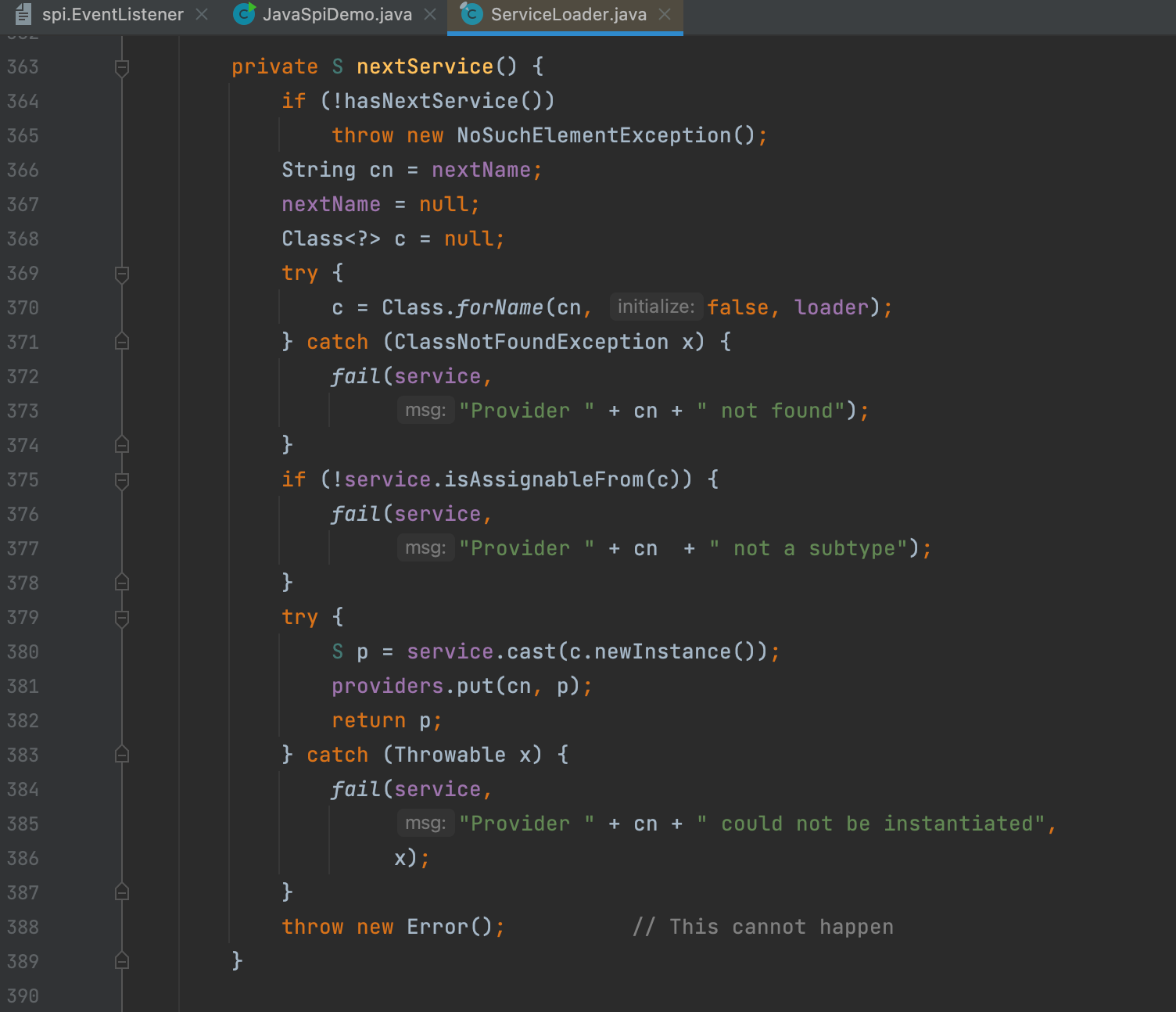
💡注意:通过此处源码可以看出,ServiceLoader实例化实现类的方式是 Class.newInstance() 方法,所以通过Java SPI实现SPI机制时,实现类必须要有无参构造方法。
优缺点
从示例代码和源码可以看出,Java实现的SPI机制比较简单,所以更容易于开发者理解和使用。也因为此会有一点缺点。
第一点就是浪费资源,虽然例子中只有一个实现类,但是实际情况下可能会有很多实现类,而Java的SPI会一股脑全进行实例化,但是这些实现了不一定都用得着,所以就会白白浪费资源。
第二点就是无法对区分具体的实现,也就是这么多实现类,到底该用哪个实现呢?如果要判断具体使用哪个,只能依靠接口本身的设计,比如接口可以设计为一个策略接口,又或者接口可以设计带有优先级的,但是不论怎样设计,框架作者都得写代码进行判断。
所以总得来说就是ServiceLoader无法做到按需加载或者按需获取某个具体的实现。
使用场景
一般适用于:
- 不需要选择具体的实现,每个被加载的实现都需要被用到
- 虽然需要选择具体的实现,但是可以通过对接口的设计来解决
例如:全局拦截器、过滤器、校验器。
我在项目中用过 javax.validation.spi.ValidationProvider ,hibernate对其做了较为全面的封装,其实现类为 org.hibernate.validator.HibernateValidator 。
Spring SPI机制
Spring实现SPI机制的核心类叫 SpringFactoriesLoader ,Spring的SPI机制约定如下:
- 配置文件必须在
META-INF/目录下,文件名必须为spring.factories - 文件内容为键值对,一个键可以有多个值,只需要用逗号分割就行,同时键值都需要是类的全限定名,键和值可以没有任何类与类之间的关系,当然也可以有实现的关系。
从约定内容可以看出,Spring的SPI机制与Java的SPI机制相比,文件约定和接口类约定都不相同。
示例
第一步,定义文件。

第二步,定义测试类。
1 | public class SpringSpiDemo { |
测试结果:

成功获取到实现对象。
实现原理
大致原理为:
- 解析
META-INF/spring.factories文件,获取实现类的全限定名。 - 反射实例化对象。
- Spring 排序。
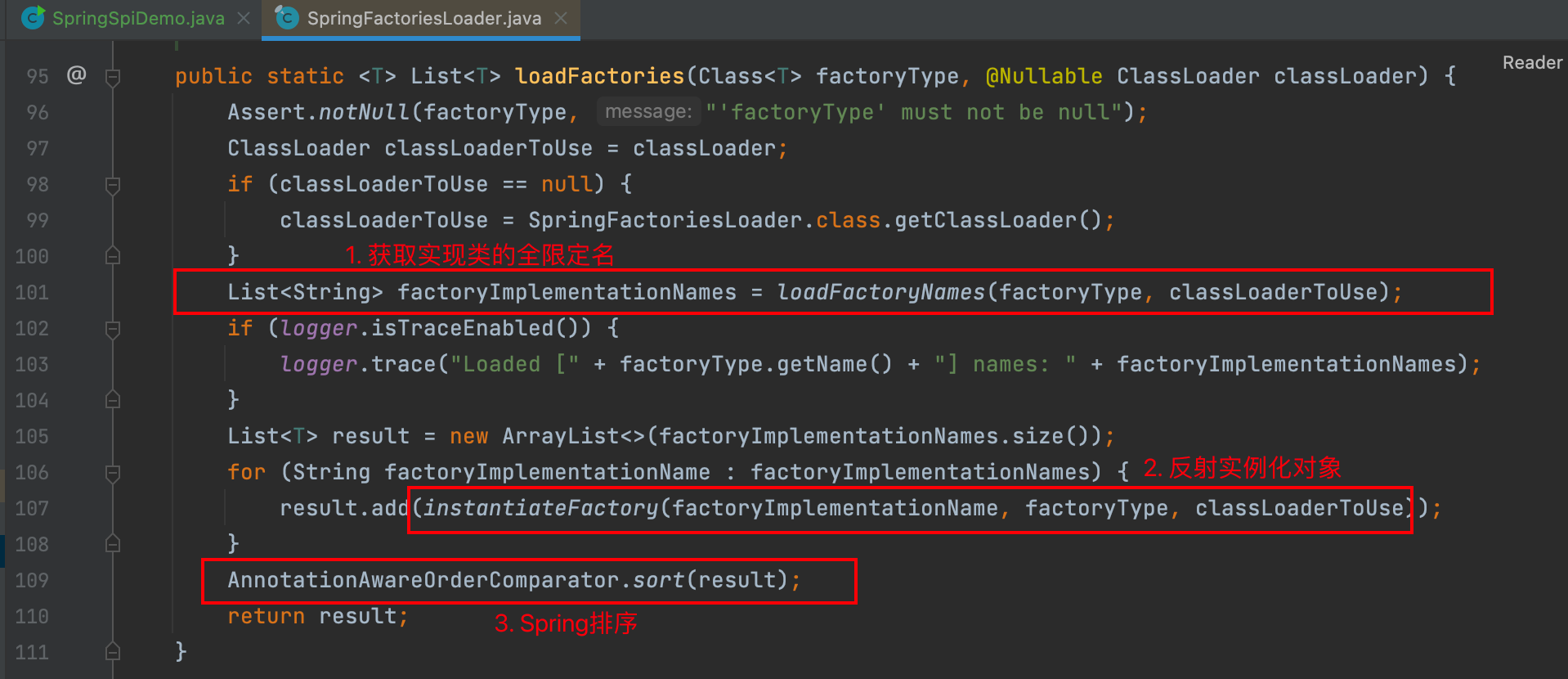
第一步,解析文件是Spring实现SPI机制的关键,它默认解析 FACTORIES_RESOURCE_LOCATION = "META-INF/spring.factories" 下的文件内容。源码如下:
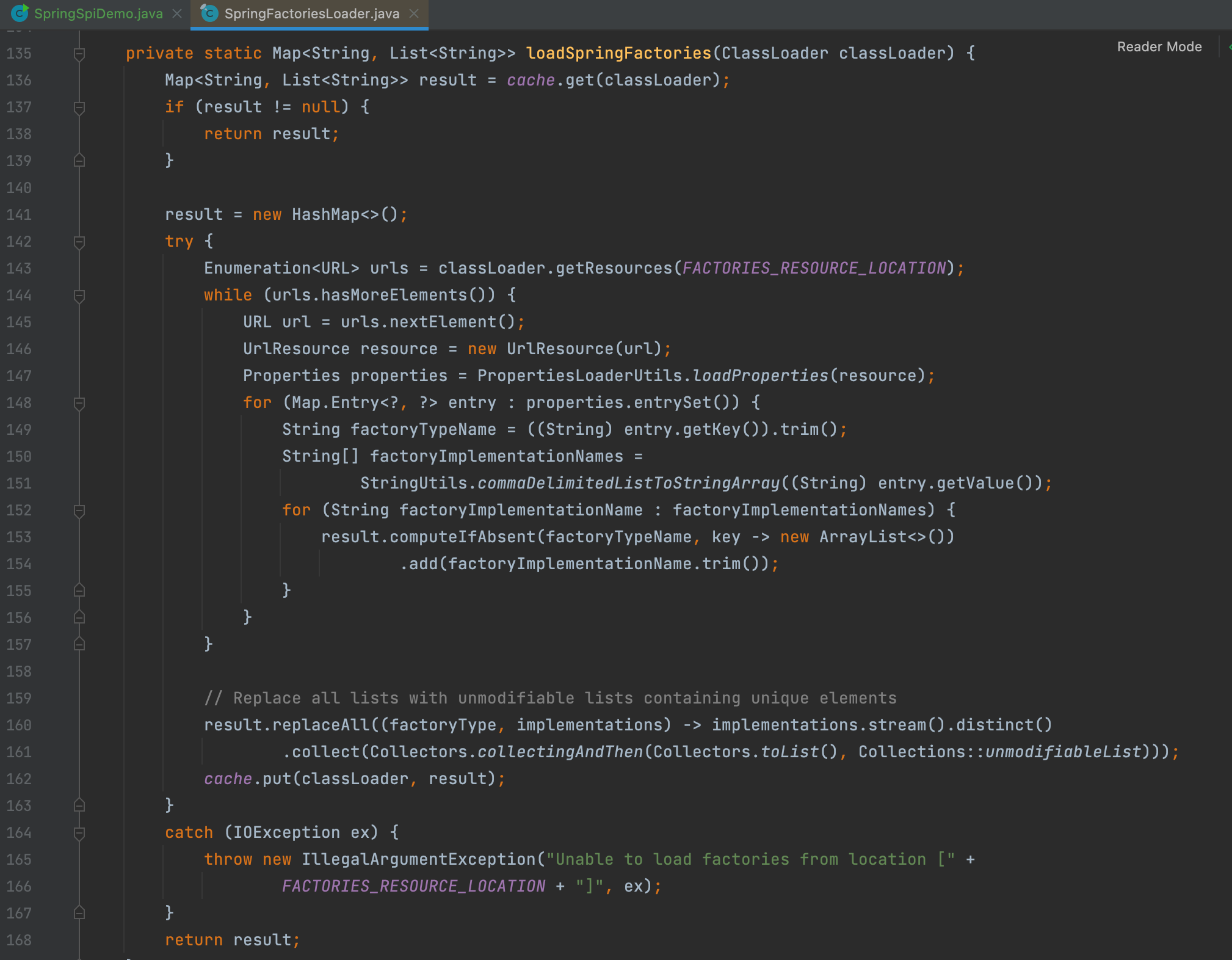
第二步,实例化对象时也是先获取Class类对象,再通过反射构造实例化对象,与Java SPI不同的是,它是使用的 Constructor.newInstance() 方法,但并不支持有参构造,还是得需要无参构造方法。
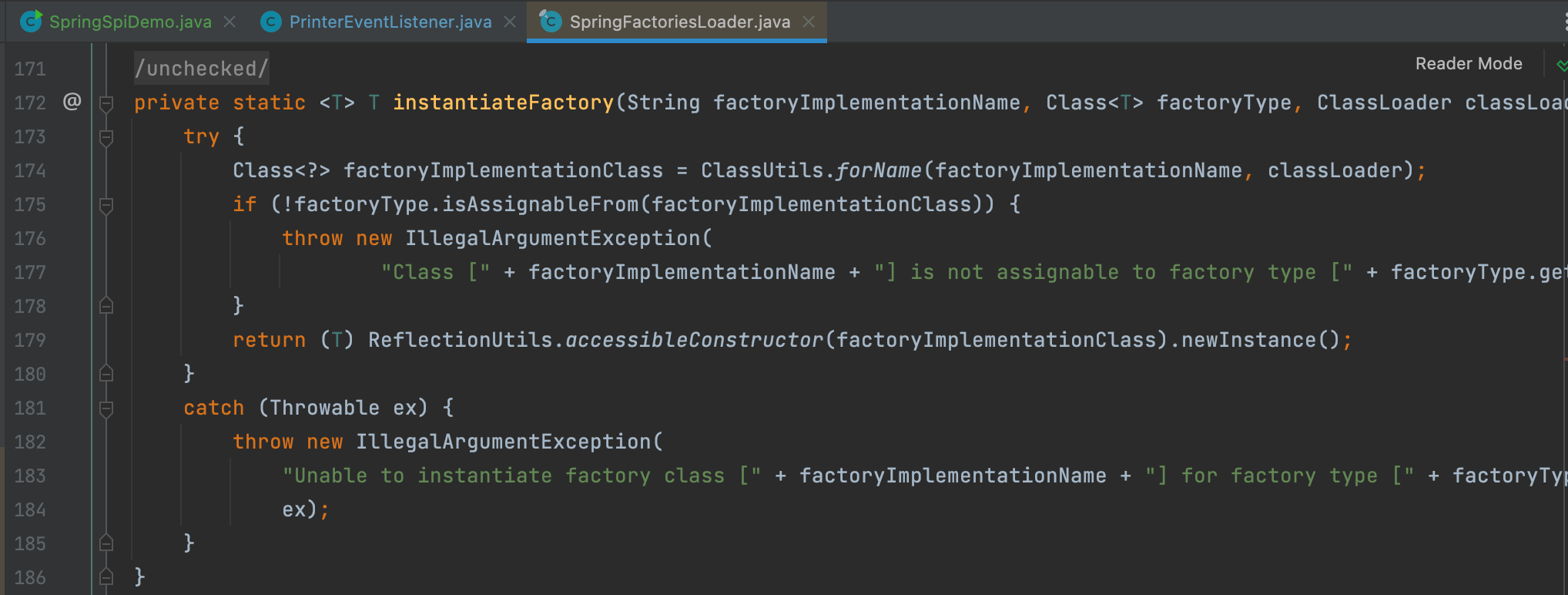
第三部,Spring内置排序功能,AnnotationAwareOrderComparator.sort(List<?> list) 方法的作用是判断对象是否实现了 Ordered 类,或者是否标记了 Order 注解。排序功能的实现类为 AnnotationAwareOrderComparator 。
这也是Spring SPI机制与Java SPI机制的不同点,ServiceLoader是按顺序加载并返回,而SpringFactoriesLoader是按顺序加载,正序排序后再返回。
使用场景
Spring的SPI机制在内部使用的非常多,尤其在SpringBoot中大量使用,SpringBoot启动过程中很多扩展点都是通过SPI机制来实现的,例如:
1、自动装配
在SpringBoot3.0之前的版本,自动装配是通过SpringFactoriesLoader来加载的。
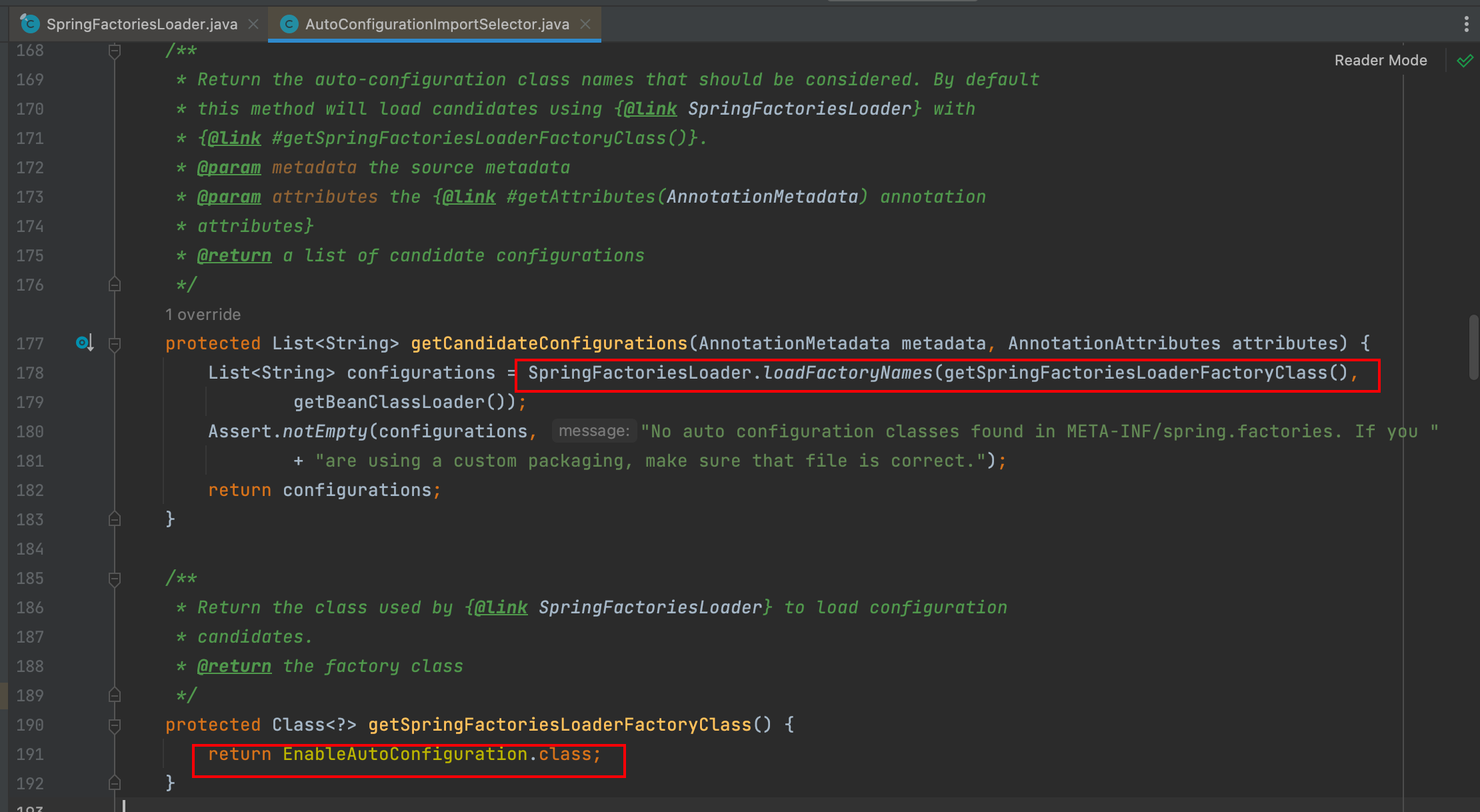
但是SpringBoot3.0之后不再使用SpringFactoriesLoader,而是Spring重新从 META-INF/spring/ 目录下的 org.springframework.boot.autoconfigure.AutoConfiguration.imports 文件中读取了。
2、PropertySourceLoader的加载
PropertySourceLoader是用来解析application配置文件的,它是一个接口。
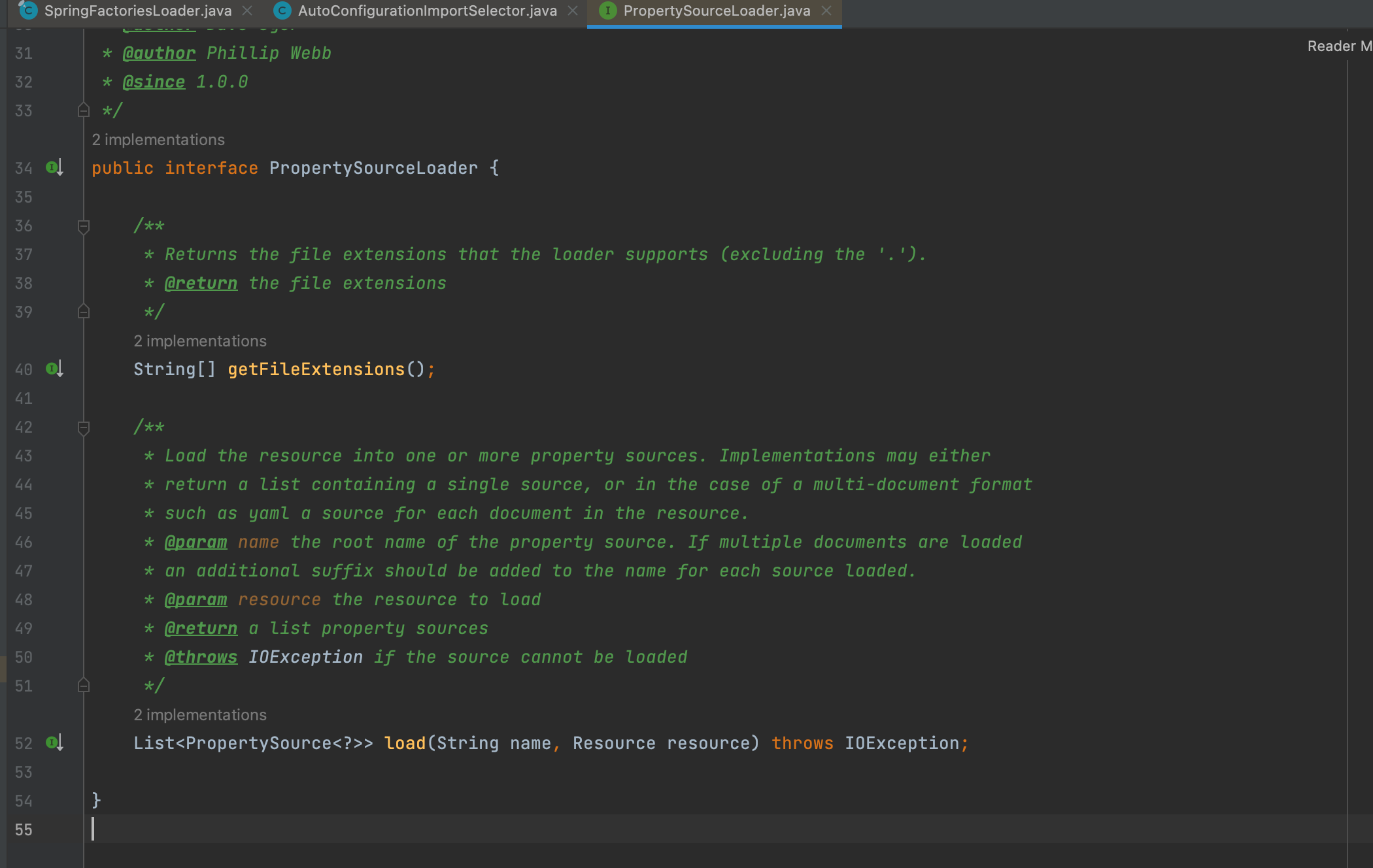
SpringBoot默认提供了 PropertiesPropertySourceLoader 和 YamlPropertySourceLoader两个实现,就是对应properties和yaml文件格式的解析。
SpringBoot在加载PropertySourceLoader时就用了SPI机制。
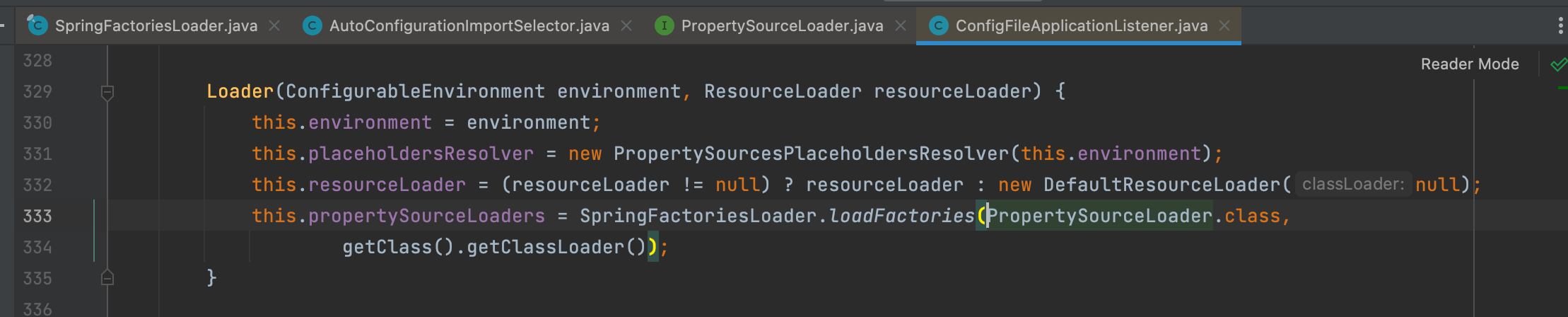
与Java SPI机制对比
首先Spring的SPI机制对Java的SPI机制对进行了一些简化,Java的SPI每个接口都需要对应的文件,而Spring的SPI机制只需要一个spring.factories文件。
其次是内容,Java的SPI机制文件内容必须为接口的实现类,而Spring的SPI并不要求键值对必须有什么关系,更加灵活。
第三点就是Spring的SPI机制提供了获取类限定名的方法loadFactoryNames,而Java的SPI机制是没有的。通过这个方法获取到类限定名之后就可以将这些类注入到Spring容器中,用Spring容器加载这些Bean,而不仅仅是通过反射。
但是Spring的SPI也同样没有实现获取指定某个指定实现类的功能,所以要想能够找到具体的某个实现类,还得依靠具体接口的设计。
所以不知道你有没有发现,PropertySourceLoader它其实就是一个策略接口,注释也有说,所以当你的配置文件是properties格式的时候,他可以找到解析properties格式的PropertiesPropertySourceLoader对象来解析配置文件。
总结
通过以上分析可以看出,实现SPI机制的核心原理就是通过IO流读取指定文件的内容,然后解析,最后加入一些自己的特性。









