Java-JVM类文件结构
简介
在Java中,被 JVM 可以理解的代码称为字节码,即扩展名为 .class 的文件,这种文件被称为字节码文件,也可以称为类文件或者Class文件。
Java使用Java编译器(javac)可以将Java代码编译为字节码存储的Class文件,其他语言也可以使用自己的编译器将代码编译成Class文件,例如JRuby通过jrubyc编译器生成、Groovy通过groovyc编译器生成、Kotlin通过kotlinc编译器生成等。
编译生成后的Class文件被JVM虚拟机执行,不受操作系统平台影响,因此具有“一次编译,到处运行”的特性。
🔔温馨提示:本章内容偏硬核,基本就是一个硬背字典的概念,建议结合 “手撕”Class文件结构 一起阅读,边看边上手最好。
类文件结构
任何一个Class文件都对应着唯一的一个类或接口的定义信息,但是反过来说,类或接口并不一定都得定义在文件里(譬如类或接口也可以动态生成,直接送入类加载器中)。
Class文件是一组紧凑排列的二进制流,,各个数据项目按照顺序排列,没有分隔符,这使得整个Class文件中存储的内容几乎全部是程序运行的必要数据,没有空隙存在。
Class文件格式采用一种类似于C语言结构体的伪结构来存储数据,这种伪结构中只有两种数据类型:“无符号数”和“表”。
无符号数属于基本的数据类型,以u1、u2、u4、u8来分别代表1个字节、2个字节、4个字节和8个字节的无符号数,无符号数可以用来描述数字、索引引用、数量值或者按照UTF-8编码构成字符串值。
表是由多个无符号数或者其他表作为数据项构成的复合数据类型,为了便于区分,所有表的命名都习惯性地以“_info”结尾。表用于描述有层次关系的复合结构的数据,整个Class文件本质上也可以视作是一张表,这张表由如下所示的数据项按严格顺序排列构成。
1 | ClassFile { |
无论是无符号数还是表,当需要描述同一类型但数量不定的多个数据时,经常会使用一个前置的容量计数器加若干个连续的数据项的形式,这时候称这一系列连续的某一类型的数据为某一类型的“集合”。用一张图可以更加清晰的了解Class文件的组成。
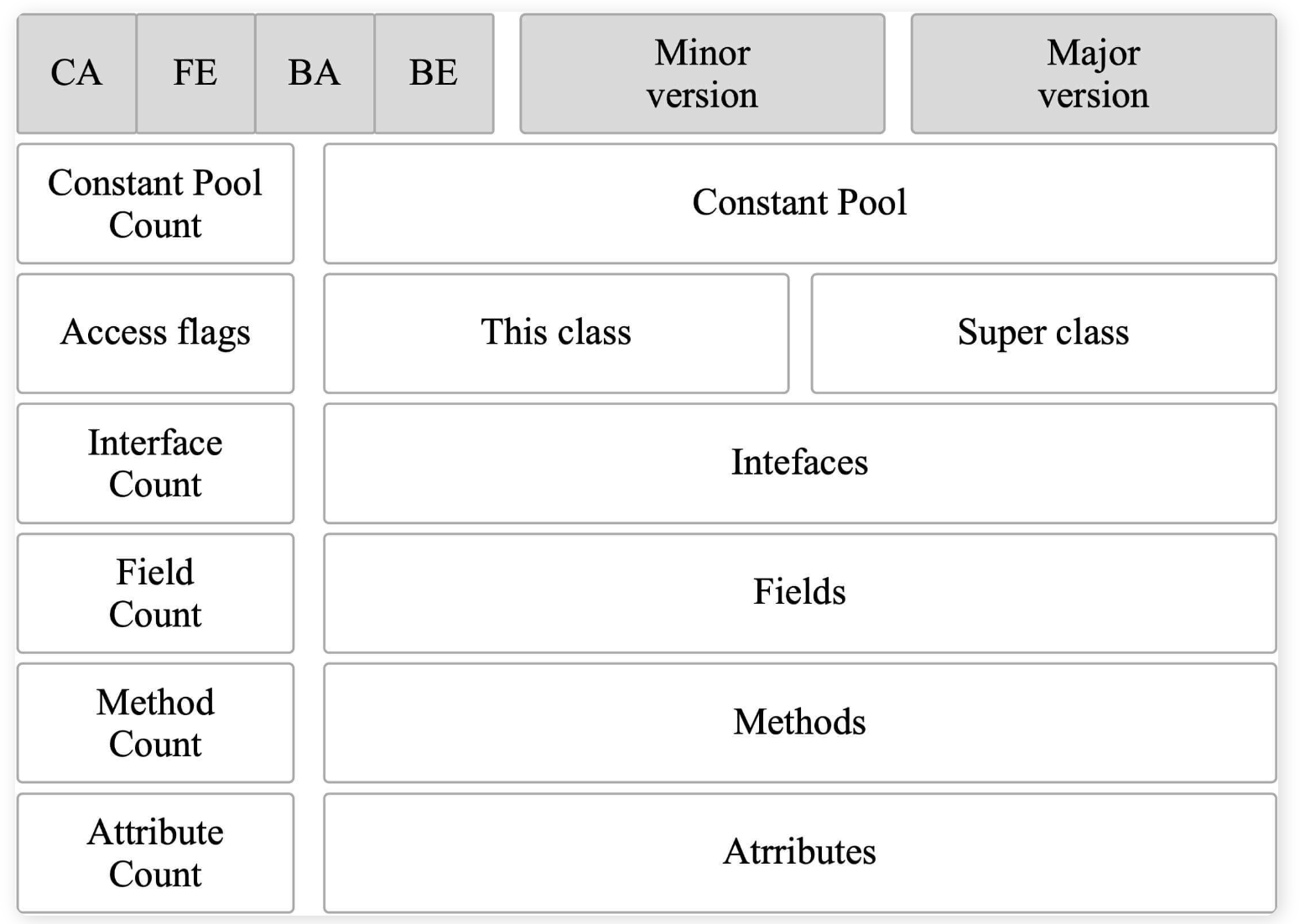
魔数
1 | u4 magic; //Class 文件的标志 |
每个Class文件的头4个字节被称为魔数(Magic Number),它的唯一作用是确定这个文件是否为一个能被虚拟机接受的Class文件。
Java 规范规定魔数为固定值:0xCAFEBABE。如果读取的文件不是以这个魔数开头,Java 虚拟机将拒绝加载它。
Class文件的版本号
1 | u2 minor_version;//Class 的小版本号 |
紧接着魔数的4个字节存储的是Class文件的版本号:第5和第6个字节是次版本号(Minor Version),第7和第8个字节是主版本号(Major Version)。
Java的版本号是从45开始的,JDK 1.1之后的每个JDK大版本发布主版本号向上加1(JDK 1.0~1.1使用了45.0~45.3的版本号),高版本的JDK能向下兼容以前版本的Class文件,但不能运行以后版本的Class文件,因为《Java虚拟机规范》在Class文件校验部分明确要求了即使文件格式并未发生任何变化,虚拟机也必须拒绝执行超过其版本号的Class文件。
常量池
1 | u2 constant_pool_count;//常量池的数量 |
常量池可以比喻为Class文件里的资源仓库,它是Class文件结构中与其他项目关联最多的数据,通常也是占用Class文件空间最大的数据项目之一,另外,它还是在Class文件中第一个出现的表类型数据项目。
常量池计数器是从 1 开始计数的,将第 0 项常量空出来是有特殊考虑的,索引值为 0 代表“不引用任何一个常量池项”。即如果constant_pool_count的十进制值为10,那么cp_info中实际的常量有9个。
Class文件结构中只有常量池的容量计数是从1开始,对于其他集合类型,包括接口索引集合、字段表集合、方法表集合等的容量计数都与一般习惯相同,是从0开始。
常量池中主要存放两大类常量:字面量(Literal)和符号引用(Symbolic References)。
- 字面量(Literals):字面量是不变的数据,主要包括数值(如整数、浮点数)和字符串字面量。例如,一个整数100或一个字符串"Hello World",在源代码中直接赋值,编译后存储在常量池中。
- 符号引用(Symbolic References):符号引用是对类、接口、字段、方法等的引用,它们不是由字面量值给出的,而是通过符号名称(如类名、方法名)和其他额外信息(如类型、签名)来表示。这些引用在类文件中以一种抽象的方式存在,它们在类加载时被虚拟机解析为具体的内存地址。
常量池中每一种常量都是一个表,这些表都有一个共同特点,就是表结构起始的第一位是u1类型的标志位(tag),代表着当前常量属于哪种常量类型。常见的常量类型如下:
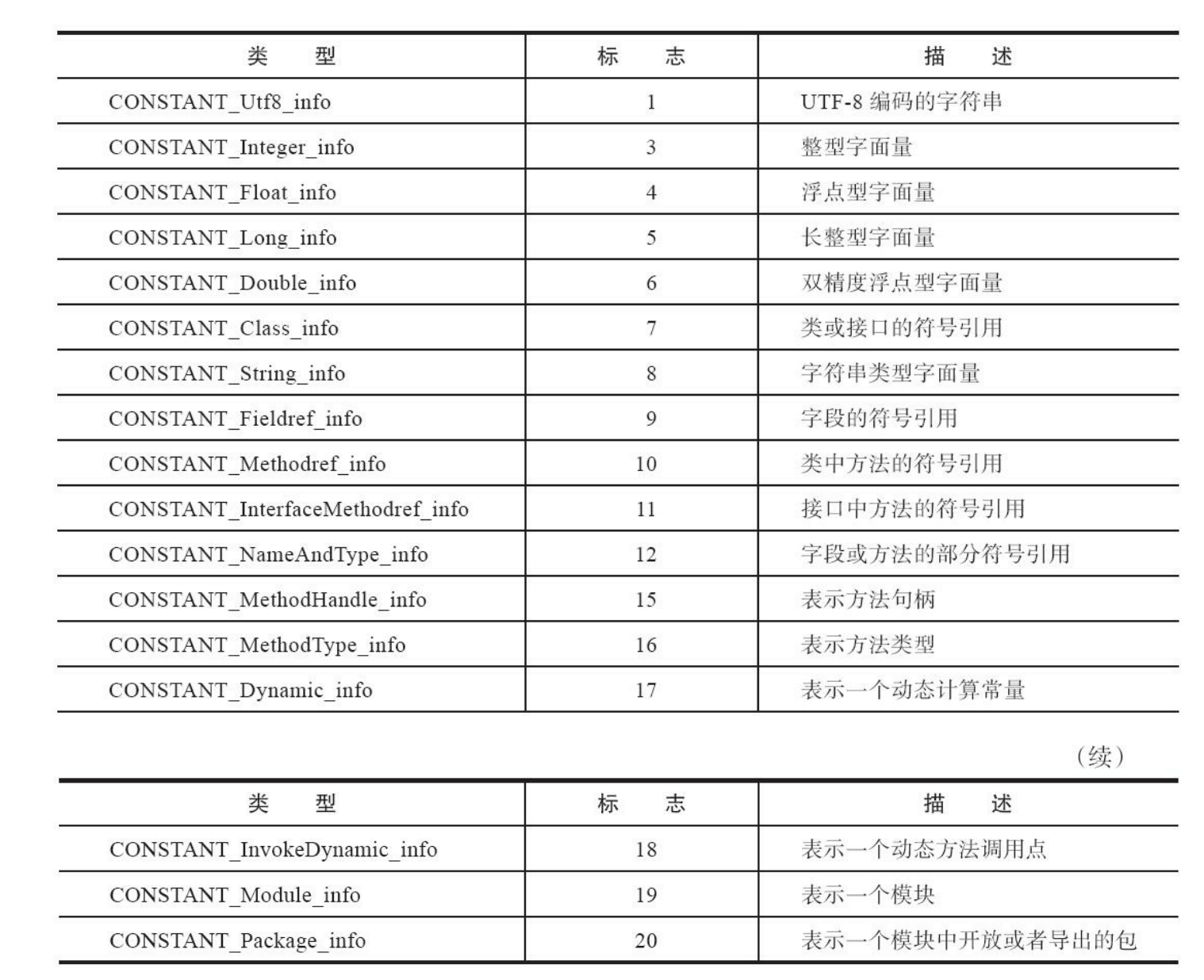
每一种常量池的表结构也是不一样的,例如CONSTANT_Utf8_info类型的结构如下:

如果tag位对应十进制为1时,后面紧接着的2个字节是字符串的长度,然后length是字符串的字节长度。
因为常量类型过多,表结构不一致,并且随着Java迭代升级,常量类型越来越多,所以JDK提供了javap工具用于分析Class文件字节码,使用 javap -verbose Xxx 命令即可查看Xxx.class文件的字节码内容。

如上图所示,Constant pool表示常量池,拿第一个常量进行分析:
#1表示第一个常量,Methodref表示它的类型(对应标志位为10,描述是“类中方法的符号引用”),#15.#37表示该常量的值,在Methodref类型中表示指向常量Class #15 和 NameAndType #37,后面的 // ... 内容是注释内容,提示用户这个常量的含义是 引用了java/lang/Object类的构造方法<init>,方法签名为()V,即无参数,返回类型为void。
仔细看一下会发现,其中有些常量似乎从来没有在代码中出现过,如“I”“V”“<init>”“LineNumberTable”“LocalVariableTable”等,这些看起来在源代码中不存在的常量是哪里来的?这部分常量的确不来源于Java源代码,它们都是编译器自动生成的,会被后面即将讲到的字段表(field_info)、方法表(method_info)、属性表(attribute_info)所引用,它们将会被用来描述一些不方便使用“固定字节”进行表达的内容,譬如描述方法的返回值是什么,有几个参数,每个参数的类型是什么。因为Java中的“类”是无穷无尽的,无法通过简单的无符号数来描述一个方法用到了什么类,因此在描述方法的这些信息时,需要引用常量表中的符号引用进行表达。
以下是部分常量类型的结构定义:


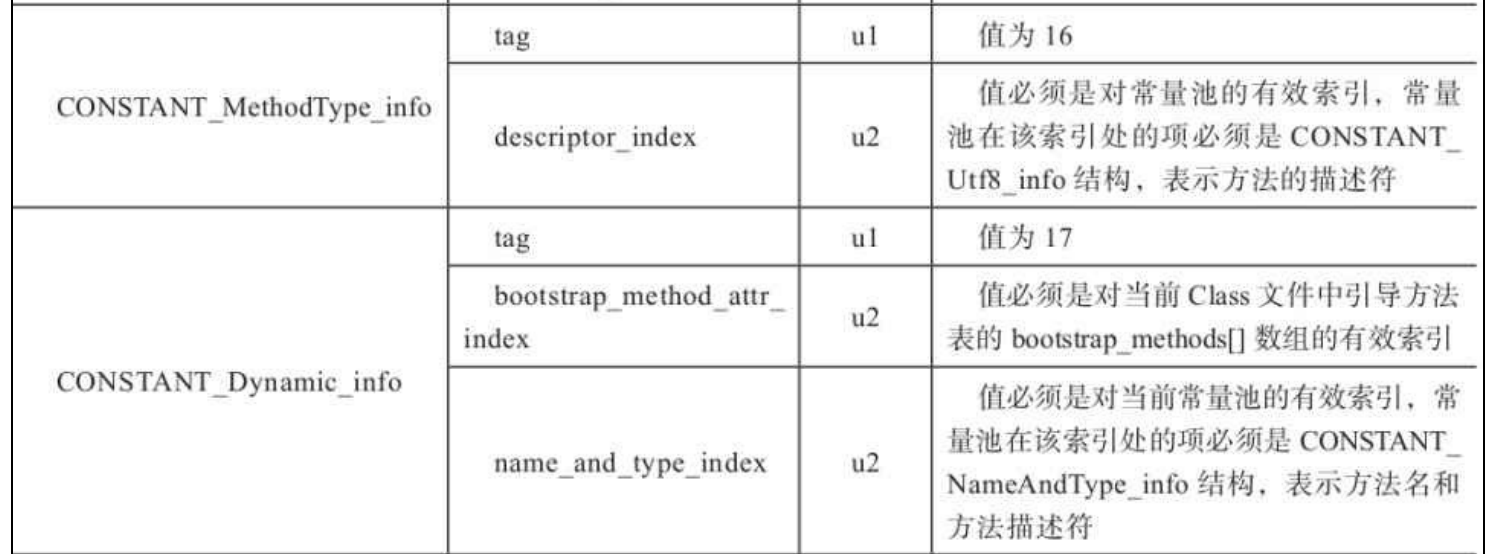

访问标志
1 | u2 access_flags;//Class 的访问标记 |
在常量池结束之后,紧接着的两个字节代表访问标志,这个标志用于识别一些类或者接口层次的访问信息,包括:这个 Class 是类还是接口,是否为 public 或者 abstract 类型,如果是类的话是否声明为 final 等等。
具体的标志位以及标志的含义如下:

访问标志要求类文件中没有使用到的标志位一律为0,然后把使用到的标志值通过按位或运算计算得到一个u2长度的十六进制。
类索引、父类索引、接口索引集合
1 | u2 this_class;//类索引 |
类索引(this_class)和父类索引(super_class)都是一个u2类型的数据,而接口索引集合(interfaces)是一组u2类型的数据的集合,Class文件中由这三项数据来确定该类型的继承关系。
类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名。由于Java语言不允许多重继承,所以父类索引只有一个,除了java.lang.Object之外,所有的Java类都有父类,因此除了java.lang.Object外,所有Java类的父类索引都不为0。
接口索引集合就用来描述这个类实现了哪些接口,这些被实现的接口将按implements关键字(如果这个Class文件表示的是一个接口,则应当是extends关键字)后的接口顺序从左到右排列在接口索引集合中。
类索引和父类索引各自指向一个类型为CONSTANT_Class_info的类描述符常量,通过CONSTANT_Class_info类型的常量中的索引值可以找到定义在CONSTANT_Utf8_info类型的常量中的全限定名字符串。
接口索引入口的第一项u2类型的数据为接口计数器(interfaces_count),表示索引表的容量。如果容量为0,则索引集合为0,后面就没有对应的字节。
字段表集合
1 | u2 fields_count;//字段数量 |
字段表(field_info)用于描述接口或者类中声明的变量。字段包括类级变量以及实例级变量,但不包括在方法内部声明的局部变量。
字段表的结构如下(从上到下、从左到右的顺序):

-
access_flags: 字段的作用域(
public,private,protected修饰符),是实例变量还是类变量(static修饰符),可否被序列化(transient 修饰符),可变性(final),可见性(volatile 修饰符,是否强制从主内存读写)。字段中 access_flags 的取值如下:

-
name_index: 对常量池的引用,表示的字段的简单名称。
相较于“全限定名”,简单名称就是指没有类型和参数修饰的方法或者字段名称,全限定名则是把类全名中的“.“换成了“/”,为了使连续的多个全限定名之间不产生混淆,在使用时最后一般会加入一个“;”号表示全限定名结束。
-
descriptor_index: 对常量池的引用,表示字段的描述符(同方法的descriptor_index描述符性质一样),描述符的作用是用来描述字段的数据类型、方法的参数列表(包括数量、类型以及顺序)和返回值。
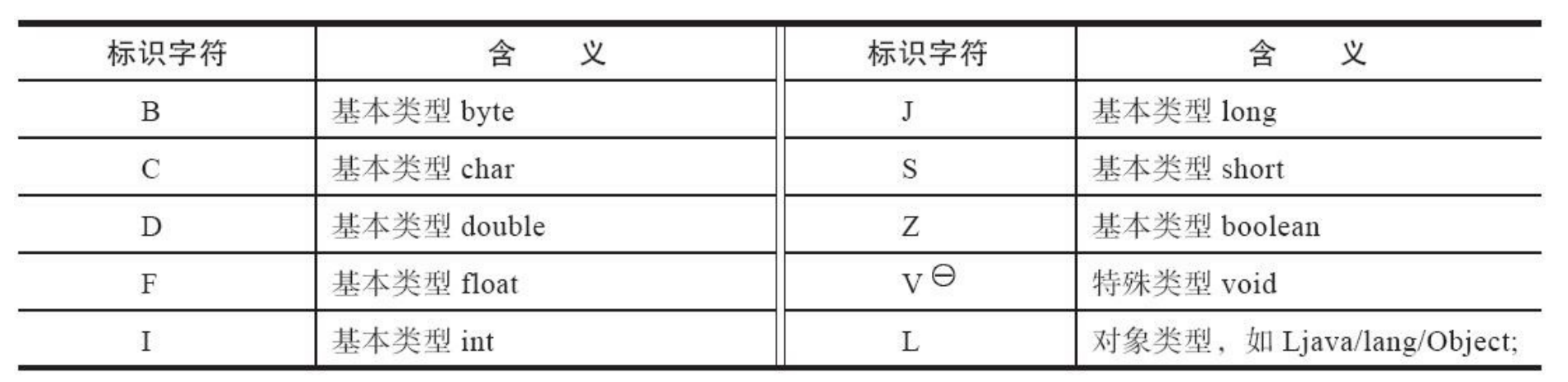
描述符一般用于字段和方法,它有如下一些规则:基本数据类 型(byte、char、double、float、int、long、short、boolean)以及代表无返回值的void类型都用一个大写字符来表示,而对象类型则用字符L加对象的全限定名来表示,对于数组类型,每一维度将使用一个前置的“[”字符来描述,如一个定义为“java.lang.String[][]”类型的二维数组将被记录成“[[Ljava/lang/String;”,一个整型数组“int[]”将被记录成“[I”。
用描述符来描述方法时,按照先参数列表、后返回值的顺序描述,参数列表按照参数的严格顺序放在一组小括号“()”之内。如方法void inc()的描述符为“()V”,方法java.lang.String toString()的描述符为“()Ljava/lang/String;”,方法int indexOf(char[]source,int sourceOffset,int sourceCount,char[]target, int targetOffset,int targetCount,int fromIndex)的描述符为“([CII[CIII)I”。
-
attributes_count: 一个字段还会拥有一些额外的属性,attributes_count 存放属性的个数。
-
attributes[attributes_count]: 存放具体属性具体内容。
方法表集合
1 | u2 methods_count;//方法数量 |
Class文件存储格式中对方法的描述与对字段的描述采用了几乎完全一致的方式,方法表的结构如同字段表一样,依次包括访问标志(access_flags)、名称索引(name_index)、描述符索引(descriptor_index)、属性表集合(attributes)几项。这些数据项目的含义也与字段表中的非常类似,仅在访问标志和属性表集合的可选项中有所区别。

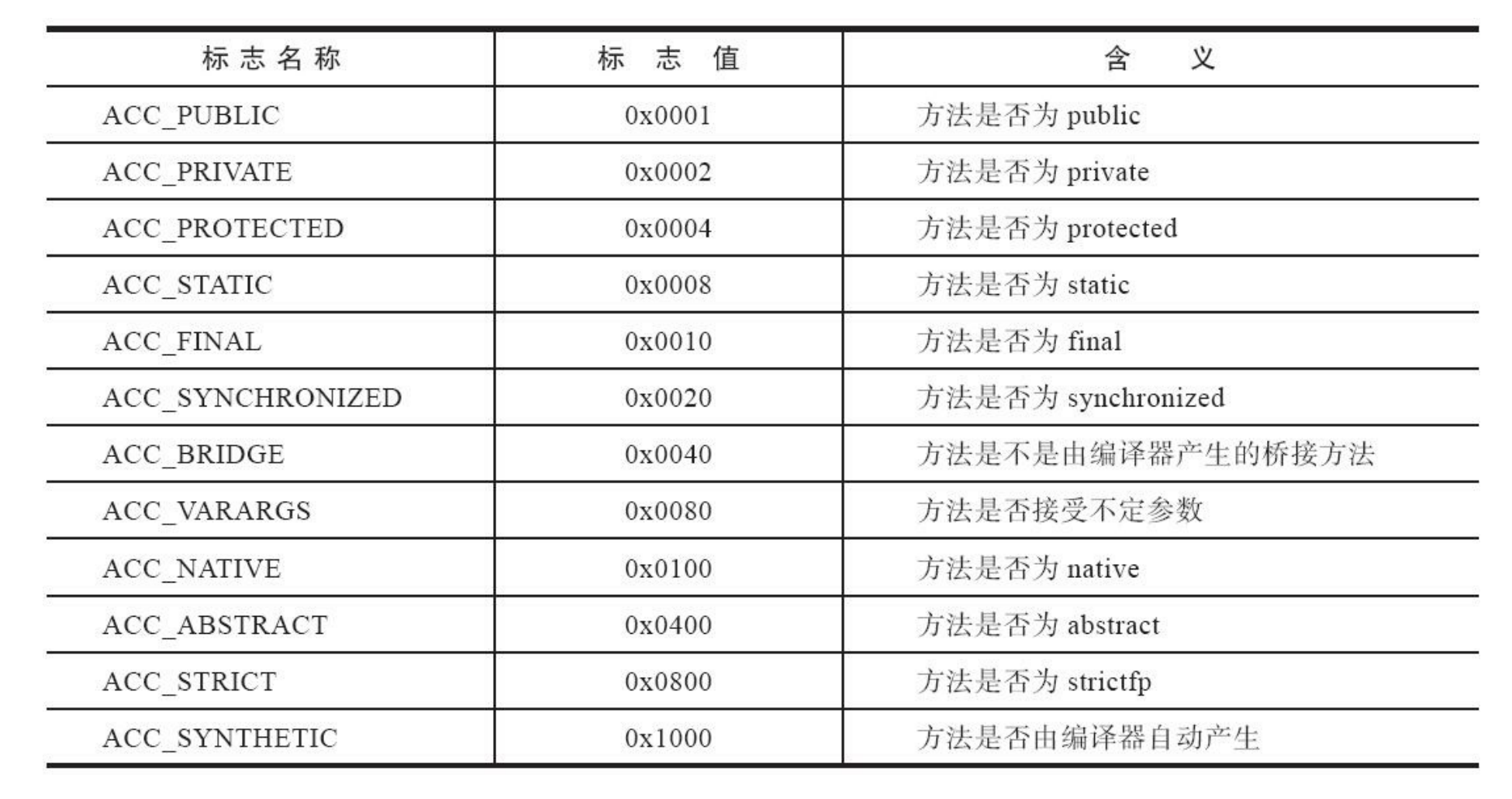
因为volatile关键字和transient关键字不能修饰方法,所以方法表的访问标志中没有了 ACC_VOLATILE标志和ACC_TRANSIENT标志。与之相对,synchronized、native、strictfp和abstract关键字可以修饰方法,方法表的访问标志中也相应地增加了ACC_SYNCHRONIZED、ACC_NATIVE、ACC_STRICTFP和ACC_ABSTRACT标志。对于方法表,所有标志位及其取值可参见如下表。
方法的定义可以通过访问标志、名称索引、描述符索引来表达清楚,而方法里的Java代码经过Javac编译器编译成字节码指令之后,存放在方法属性表集合中一个名为“Code”的属性里面,然后通过属性索引在属性表中查找。
与字段表集合相对应地,如果父类方法在子类中没有被重写(Override),方法表集合中就不会出现来自父类的方法信息。但同样地,有可能会出现由编译器自动添加的方法,最常见的便是类构造器“<clinit>()”方法和实例构造器“<init>()”方法。
在Java语言中,要重载(Overload)一个方法,除了要与原方法具有相同的简单名称之外,还要求必须拥有一个与原方法不同的特征签名。特征签名是指一个方法中各个参数在常量池中的字段符号引用的集合,也正是因为返回值不会包含在特征签名之中,所以Java语言里面是无法仅仅依靠返回值的不同来对一个已有方法进行重载的。但是在Class文件格式之中,特征签名的范围明显要更大一些,只要描述符不是完全一致的两个方法就可以共存。也就是说,如果两个方法有相同的名称和特征签名,但返回值不同,那么也是可以合法共存于同一个Class文件中的。
属性表集合
1 | u2 attributes_count;//此类的属性表中的属性数 |
在 Class 文件中,字段表,方法表中都可以携带自己的属性表集合,以用于描述某些场景专有的信息。与 Class 文件中其它的数据项目要求的顺序、长度和内容不同,属性表集合的限制稍微宽松一些,不再要求各个属性表具有严格的顺序,并且只要不与已有的属性名重复,任何人实现的编译器都可以向属性表中写 入自己定义的属性信息,Java 虚拟机运行时会忽略掉它不认识的属性。
《Java虚拟机规范》有一些预定属性,要求所有Java虚拟机实现都应该能识别这些属性,部分属性如下:




对于每一个属性,它的名称都要从常量池中引用一个CONSTANT_Utf8_info类型的常量来表示,而属性值的结构则是完全自定义的,只需要通过一个u4的长度属性去说明属性值所占用的位数即可。一个符合规则的属性表应该满足下表中所定义的结构。